
Private Blogs werden oft aufgegeben, und auch auf kommerziellen Websites verschwinden Inhalte. Diese sind dann nicht mehr unter der bisherigen Adresse erreichbar oder wurden nachträglich verändert. Außerdem gibt es Angebote, deren Inhalte sich dynamisch ändern, etwa Seiten mit Börsenkursen oder Wetterdaten. Für ein Archiv speichern Sie Webseiten ganz einfach über den Browser. Sie können die Seiten später ohne Internetverbindung lesen oder für Recherchen nutzen. Zur Verfügung stehen dabei die Dateiformate HTML oder PDF. Mit Browsererweiterungen lassen sich Komfort und Ergebnis verbessern. Der Artikel stellt außerdem Software vor, mit der Sie gespeicherte Dateien durchsuchen und besser verwalten können.
Service: Befehlszeilen und Konfigurationsdateien zu diesem Artikel können Sie über https://m6u.de/WEBAR herunterladen.
Webseiten im Browser speichern
Jeder Browser bietet eine Funktion, um die gerade geöffnete Webseite zu speichern. Am schnellsten rufen Sie den Speichern-Dialog über die Tastenkombination Strg-S auf oder nach Rechtsklick und „Seite speichern unter“.
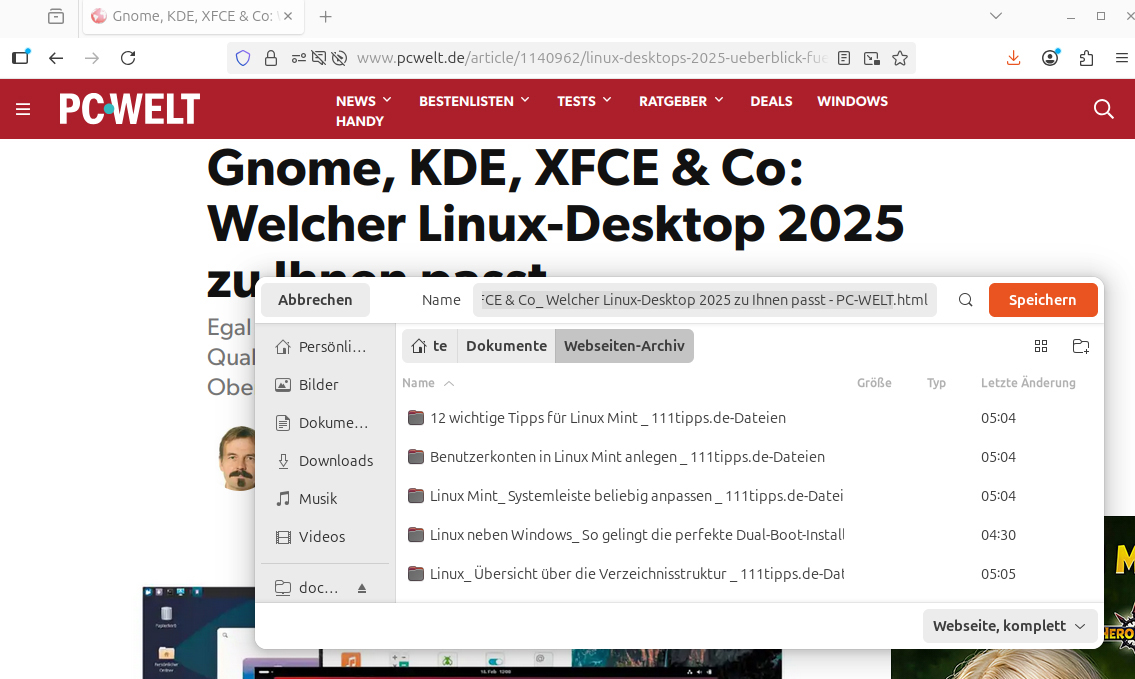
Firefox: Im Speichern-Dialog wählen Sie rechts unten das gewünschte Format aus. „Website, komplett“ sichert die Seite in einer HTML-Datei, Bilder und weitere Elemente landen in einem Ordner mit dem gleichen Namen. Der HTML-Code wird so angepasst, dass die Mediendateien aus dem Ordner geladen werden – und nicht von der ursprünglichen Webadresse. Dadurch ist es möglich, die Seite offline inklusive Bilder zu lesen.
Beim Format „Website, nur HTML“ speichert Firefox die Webseite ohne Anpassungen. Die Original-URLs von Bildern und anderen Elementen bleiben erhalten. Wenn Sie die HTML-Datei im Browser öffnen, werden die Elemente aus dem Internet geladen, solange sie noch verfügbar sind. Andernfalls sehen Sie nur die Textinhalte. Bei Auswahl von „Textdateien“ wird nur der sichtbare Text einer Webseite kopiert.
Firefox bietet einen Lesemodus, den Sie mit der Tastenkombination Strg-Alt-R oder per Klick auf das zugehörige Icon rechts in der Adressleiste aktivieren. Der Browser zeigt dann Text und Bilder einer Webseite an, aber ohne Navigationselemente oder Seitenleiste. Dabei bleibt das Layout oft nicht erhalten. Etwa eingebettete Videos oder Tabellen werden nicht immer korrekt dargestellt. Wer hauptsächlich am Text interessiert ist, kann auch die Leseansicht über Strg-S in einer Datei speichern.
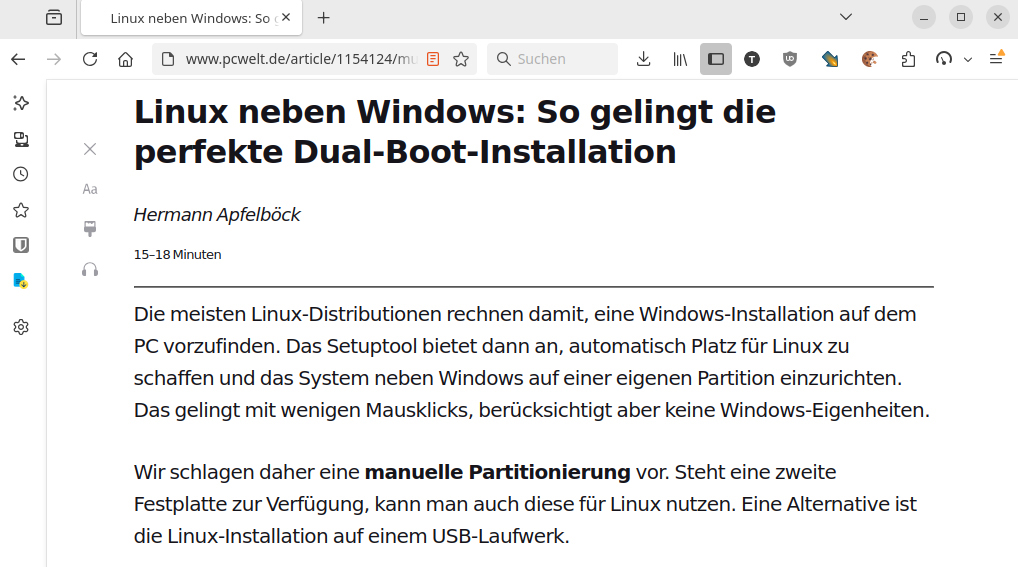
Google Chrome und Chromium: Beim Speichern können Sie zwischen „Webseite, vollständig“ und „Webseite, nur HTML“ wählen. Das Ergebnis entspricht jenem von Firefox. „Webseite, Einzeldatei“ sichert die Webseite im MHTML-Format. Achten Sie darauf, dass der Dateiname die Endung „.mhtml“ erhält. Dabei entsteht dann eine einzelne Datei, in die auch die Bilddateien eingebettet sind. Eine MHTML-Datei kann daher auch ohne Internetverbindung komplett und ohne Layoutverlust im Browser angezeigt werden. Allerdings unterstützen nur auf Chromium basierende Browser das Format, etwa auch Microsoft Edge, Opera und Vivaldi. Firefox kann dieses Dateiformat nicht anzeigen.
Alle Browser: Das PDF-Format kann eine Alternative zu HTML sein. Rufen Sie die Druckfunktion mit Strg-P auf und wählen Sie unter „Ziel“ den Eintrag „Als PDF speichern“. In der Druckvorschau sehen Sie das Ergebnis. Unnötige Elemente um den Haupttext herum fehlen meist, teilweise verbleiben aber Platzhalter im Dokument, etwa von eingebetteten Videos oder Werbung. Die Textebene in den PDFs ist durchsuchbar und man kann Inhalte markieren und kopieren.
Webseiten mit einer Erweiterung speichern
Die Browsererweiterung Singlefile (https://www.getsinglefile.com) bietet nützliche Funktionen, um Webseiten schnell und optimiert zu speichern. Sie können die Erweiterung in Firefox, Google Chrome oder Chromium installieren. Folgen Sie den Links unter „Download“ für den gewünschten Browser.
Sie starten die Erweiterung über einen Rechtsklick auf die Webseite und das Menü „SingleFile –› Speichern der Webseite mit SingleFile“. Sie können außerdem „Speichern alle Tabs“ verwenden. Singlefile speichert die Seiten im voreingestellten Downloadverzeichnis. Wenn Sie andere Zielordner angeben wollen, aktivieren Sie in den Einstellungen der Erweiterung unter „Dateiname“ die Option „Dialogfenster ‚Sichern als‘ zur Bestätigung des Dateinamens öffnen“. Singlefile speichert Webseiten in einer einzelnen Datei, die auch die Daten der Bilddateien enthält.
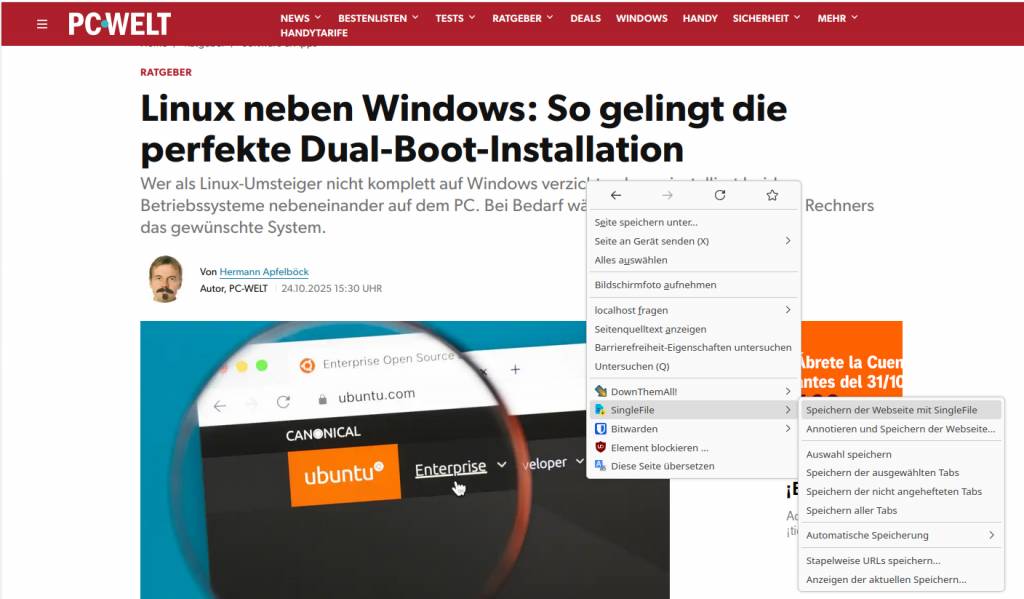
Eine weitere Funktion rufen Sie über „SingleFile –› Annotieren und Speichern der Webseite“ auf. Über die Schaltflächen in der Symbolleiste können Sie Notizen hinzufügen und Abschnitte farblich markieren. Per Klick auf „Die Seite zur besseren Lesbarkeit formatieren“ blenden Sie unnötige Elemente aus. Abschließend klicken Sie ganz rechts auf das Icon „Speichern der Webseite“. Ebenfalls nützlich: Über „SingleFile –› Stapelweise URLs speichern“ rufen Sie ein Fenster auf, in dem Sie mehrere URLs hinzufügen können. Nach einem Klick auf „Seiten speichern“ sichert Singlefile die angegebenen Webseiten.
Singlefile Per Script automatisieren
Das Kommandozeilentool Singlefile-cli (https://github.com/gildas-lormeau/single-file-cli) eignet sich für die Verwendung in einem Script. Es arbeitet nur mit Chromium-Browsern zusammen, also nur mit Chromium oder Google Chrome. Schließen Sie den Browser, bevor Sie das Tool verwenden. Ein Beispielaufruf unter Ubuntu (Snap-Installation) kann so aussehen:
./single-file-x86_64-linux --browser-executable-path /snap/bin/chromium --output-directory $HOME/Dokumente/Webseiten-Archiv --browser-args "[\"--user-data-dir=$HOME/snap/chromium/common/chromium\"]" --urls-file $HOME/Dokumente/URLs.txtNutzer von Linux Mint verwenden
./single-file-x86_64-linux --output-directory $HOME/Dokumente/Webseiten-Archiv --browser-args "[\"--user-data-dir=$HOME/.config/chromium\"]" --urls-file $HOME/Dokumente/URLs.txtDer hinter „–output-directory“ angegebene Pfad muss existieren. „$HOME/Dokumente/URLs.txt“ enthält die Liste mit den gewünschten URLs – eine pro Zeile. Die Angabe hinter „–browser-args“ ist nötig, damit Chromium das Standard-Benutzerprofil verwendet. Achtung: Das Verfahren setzt voraus, dass Sie die URLs im Browser bereits einmal geöffnet und eventuelle Meldungen bestätigt haben (etwa die DSGVO-Zustimmung). Andernfalls landet das Abfrage-Popup in der gespeicherten Datei und lässt sich nachträglich nicht wegklicken.
Gespeicherte Inhalte durchsuchen
Linux-Dateimanager bieten eine Suchfunktion für Dateiinhalte, um Informationen in gespeicherten HTML- oder PDF-Dateien zu finden. Ubuntu-Nutzer klicken auf das Icon mit der Lupe in der Symbolleiste und dann auf das Icon „Suchergebnisse filtern“ rechts neben der Eingabezeile. Klicken Sie hier auf „Gesamter Text“ und geben Sie den Suchbegriff ein. Der Dateimanager von Linux Mint zeigt nach einem Klick auf das Lupensymbol die Eingabezeile „Nach Inhalten suchen“ an. Beide Dateimanager liefern die Dateien aus, die den Suchbegriff enthalten.
Das Tool Docfetcher (https://docfetcher.sourceforge.io) ist hier deutlich besser. Es unterstützt alle gängigen Office-Dateiformate sowie HTML und PDF. Docfetcher zeigt nach einer Suche nicht nur die Dateinamen, sondern im Vorschaubereich den Inhalt mit hervorgehobener Fundstelle. Sie erkennen daher sofort, ob die gewünschte Information enthalten ist.
Sie können Docfetcher unter Ubuntu über das Anwendungszentrum als Snap-Paket installieren. Im Downloadbereich des Projekts stehen außerdem ZIP-Archive für alle Linux-Systeme bereit. Nach dem Entpacken starten Sie „DocFetcher.sh“. Die benötigte Java-Laufzeitumgebung ist im Download bereits enthalten.
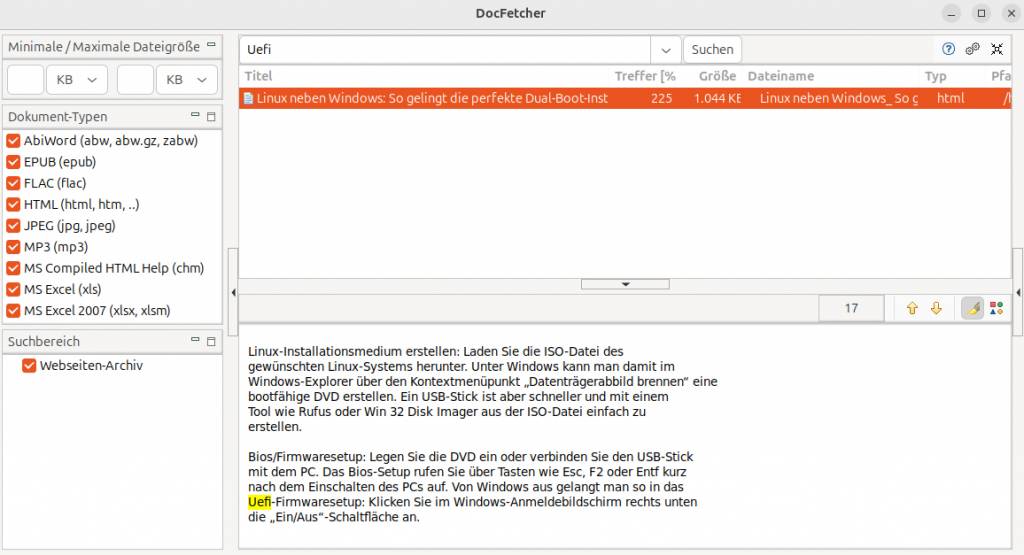
Docfetcher benötigt zunächst einen Suchindex. Klicken Sie mit der rechten Maustaste in das leere Feld unter „Suchbereich“ und gehen Sie im Menü auf „Index erstellen aus –› Ordner“. Nach Auswahl des Ordners und Klick auf „Start“ beginnt die Indexierung.
Geben Sie einen Suchbegriff ein und klicken Sie auf „Suchen“. Über die Schaltflächen mit dem Pfeil nach unten/oben gelangen Sie zur nächsten/vorherigen Fundstelle. HTML-Dateien zeigt Docfetcher standardmäßig mit dem integrierten Webbrowser an und die Fundstellen werden nicht hervorgehoben. Über die Schaltfläche ganz rechts über dem Vorschaubereich schalten Sie in den Textmodus, der sich für die Suche besser eignet.
Mehrere durch Leerzeichen getrennte Begriffe verknüpft Docfetcher mit einem logischen „OR“. Das Programm findet dann alle Dokumente, in denen einer der Begriffe oder beide vorkommen. Sie können das durch ein explizites „AND“ zwischen den Suchbegriffen ändern. Stehen Begriffe wie
"Linux Mint"in Anführungszeichen, dann wird nach der exakten Wortfolge gesucht. Weitere Informationen zur Suchsyntax finden Sie in der Hilfe, die nach dem Programmstart im Vorschaufenster zu sehen ist.
Webseiten mit Karakeep archivieren
Karakeep (https://karakeep.app) ist eine Webanwendung, um URLs, Webseiten, Bilder und Notizen zu speichern. Die Inhalte können durchsucht werden und lassen sich mit Anmerkungen und Tags versehen. Die Installation erfolgt in einem Docker-Container. Richten Sie im Terminal zuerst Docker mit der Erweiterung „compose“ ein:
sudo apt install docker-compose-v2Damit sich Docker als Standardbenutzer verwenden lässt, fügen Sie Ihr Benutzerkonto zur Gruppe „docker“ hinzu:
sudo usermod -aG docker [User]Den Platzhalter „[User]“ ersetzen Sie durch Ihren Benutzernamen. Starten Sie Linux neu, damit die Änderung wirksam wird.
Laden Sie über https://m6u.de/WEBAR die Dateien „karakeep.env“ und „docker-compose.yml“ herunter. Danach öffnen Sie „karakeep.env“ in einem Texteditor. Erzeugen Sie im Terminal mit
openssl rand -base64 36eine zufällige Zeichenkette, die Sie hinter „NEXTAUTH_SECRET=“ einfügen. Eine weitere, neue Zeichenkette fügen Sie hinter „MEILI_MASTER_KEY=“ ein. Speichern Sie die Datei und wechseln Sie im Terminal in den Ordner, in dem die heruntergeladenen Dateien liegen. Dort starten Sie mit
docker compose upden Container neu. Nach Abschluss der Einrichtung rufen Sie im Webbrowser „http://localhost:3000“ auf. Klicken Sie auf „Sign up“ und legen Sie ein Benutzerkonto an. Dieses erste Benutzerkonto erhält administrative Rechte. Klicken Sie auf das Icon oben rechts und wählen Sie im Menü „User Settings“. Unter „Interface Language“ stellen Sie „German“ als Sprache für die Oberfläche ein. Nach einem Klick auf „Zurück zur App“ erstellen Sie den ersten Eintrag.
Fügen Sie unter „Neuer Eintrag“ die gewünschte URL-Adresse ein und klicken Sie auf „Speichern“. Nachdem der Vorgang abgeschlossen ist, sehen Sie ein Vorschaubild und den Titel der Webseite. Über „…“ können Sie „Bearbeiten“ wählen und bei Bedarf Titel, Beschreibung und Zusammenfassung anpassen sowie unter „Tags“ Markierungen vergeben. Die Schaltfläche mit den zwei Pfeilen führt zur Leseansicht, in der Sie Text und Bilder der Webseite sehen. Der Docker-Container wird beendet, wenn Sie im Terminal Strg-C drücken oder das Fenster schließen. Beim nächsten Linux-Start steht Karakeep automatisch zur Verfügung.
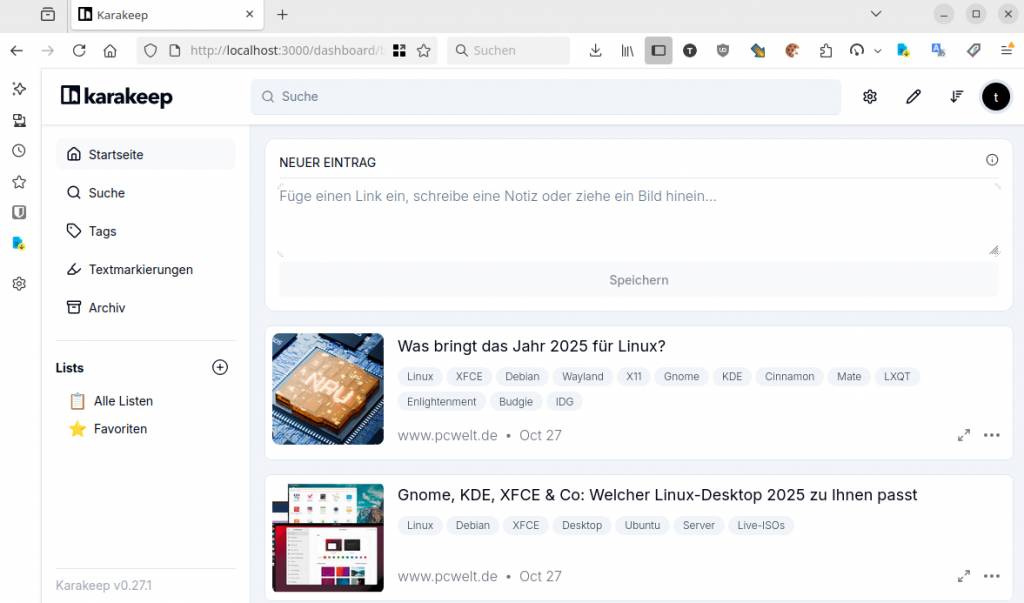
Karakeep zusammen mit Singlefile verwenden
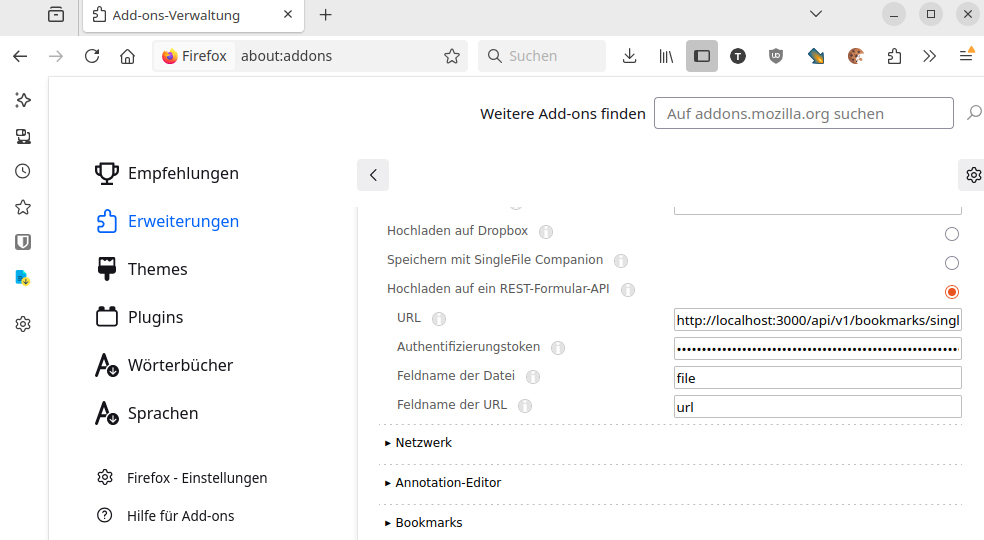
Die Browsererweiterung Singlefile kann Webseiten direkt in Karakeep speichern. In den Karakeep-Benutzereinstellungen erzeugen Sie unter „API-Schlüssel“ zuerst einen neuen Schlüssel, den Sie in die Zwischenablage kopieren. In den Singlefile-Einstellungen aktivieren Sie dann unter „Datei-Ziel“ die Option „Hochladen auf ein REST-Formular-API“. Hinter „Authentifizierungstoken“ fügen Sie den API-Schlüssel ein. Hinter „URL“ gehört diese Adresse: http://localhost:3000/api/v1/bookmarks/singlefile. „Feldname der Datei“ erhält einfach den Eintrag „file“ und „Feldname der URL“ den Wert „url“. Für bessere Ergebnisse und einen reduzierten Datenumfang setzen Sie unter „HTML-Inhalt“ ein Häkchen vor „Rahmen entfernen“. Unter „Formatvorlagen“ aktivieren Sie „CSS-Inhalte komprimieren“ und „Doppelte Formatvorlagen zusammenfassen“.
Wenn Sie jetzt eine Webseite über den Kontextmenüeintrag „SingleFile –› Speichern der Webseite mit SingleFile“ archivieren, erscheint nach kurzer Zeit ein neuer Eintrag in Karakeep.
KI-Nutzung in Karakeep aktivieren
Mit Hilfe von KI (ChatGPT oder Ollama) kann Karakeep Tags und Zusammenfassungen automatisch erzeugen. Entfernen Sie dafür in der Datei „karakeep.env“ das Kommentarzeichen („#“) vor „OPENAI_API_KEY=“, wenn Sie ChatGPT verwenden möchten. Dahinter tragen Sie den kostenpflichtigen API-Schlüssel ein, den Sie über https://platform.openai.com/api-keys erzeugen.
Die Verwendung eines selbst gehosteten KI-Modells ist kostenlos und Karakeep arbeitet auch mit Ollama zusammen. Installieren Sie danach Ollama mit
wget https://ollama.com/install.sh && sh install.shund laden Sie die Modelle herunter:
ollama pull llama3.2:latest
ollama pull llava:latestSie können für bessere Ergebnisse auch größere Modelle verwenden (siehe https://ollama.com/search), wenn die Hardware genügend Leistung bietet.
In der Datei „karakeep.env“ entfernen Sie alle Kommentarzeichen vor den Variablen unterhalb von „#Ollama“. Hinter „OLLAMA_BASE_URL=“ tragen Sie
http://[Meine-IP]:11434ein. Den Platzhalter „[Meine-IP]“ ersetzen Sie durch die IP-Adresse Ihres Rechners.
Damit Ollama auf dieser IP lauscht, passen Sie die Konfiguration an. Mit
sudo systemctl edit ollama.serviceöffnen Sie die Konfigurationsdatei des Dienstes, fügen die zwei Zeilen
[Service]
Environment="OLLAMA_HOST=0.0.0.0"unterhalb der zweiten Zeile ein und speichern die Datei. Danach starten Sie
sudo systemctl daemon-reload
sudo systemctl restart
ollama.serviceden Dienst neu. Erstellen Sie dann den Container erneut:
docker compose upWenn Karakeep noch im Browser geladen ist, aktualisieren Sie die Seite mit Strg-R. Neu hinzugefügte Elemente versieht Karakeep jetzt automatisch mit Tags und Zusammenfassungen. Bei bereits vorhandenen Einträgen klicken Sie auf „…“ und dann auf „Aktualisieren“.