

Mit Hilfe von Künstlicher Intelligenz lässt sich gesprochener Text verschriftlichen und übersetzen. Unter Linux und mit Audacity kann man diese Technik kostenlos und ohne Onlinekonto nutzen.
Durch die rasche Entwicklung im Bereich Künstliche Intelligenz können PCs inzwischen Aufgaben erledigen, die noch vor einigen Jahren undenkbar erschienen. Bei der Spracherkennung und Übersetzungen in andere Sprachen bietet KI bereits so gute Qualität, dass sich die Nachbearbeitung auf ein Minimum beschränkt. Interessant sind die Funktionen für alle, die gesprochene Sprache mit einem Text unterstützen wollen. Dabei kann es sich um Audioinhalte jeder Art handeln, beispielsweise Podcasts, Aufzeichnungen von Audio/Video-Konferenzen, Musik oder auch Filme. Voraussetzung ist, dass die Worte deutlich zu hören und wenig Störgeräusche vorhanden sind.
Besonders komfortabel ist die Nutzung des Audioeditors Audacity, der sich mit KI-Modulen erweitern lässt. Für Linux gibt es (Stand November 2024) jedoch keine installierbare Version mit KI-Funktionen, weshalb man die Software selbst zusammenstellen muss. Das Programm arbeitet bei der Transkription mit Sprachmodellen auf dem Rechner, benötigt also keine Internetverbindung und kein Konto bei Open AI.
Service: Für die automatische Transkription und Übersetzung mehrerer Dateien können Sie unabhängig von Audacity ein Python-Script verwenden, das wir in diesem Artikel vorstellen. Die Downloads zu diesem Artikel und weiterführende Informationen finden Sie überhttps://m6u.de/VTTT.
Audacity unter Linux einrichten
Mit Audacity (https://github.com/audacity/audacity) kann man Audio vom Mikrofon und anderen Quellen aufnehmen oder vorhandene Audiodateien bearbeiten und exportieren. Das zusätzliche Openvino-Plug-in integriert in Audacity einige KI-Werkzeuge für die Audioverarbeitung – beispielsweise für Rauschunterdrückung, Separation in mehrere Audiospuren (Instrumente, Gesang), automatische Erzeugung von Musik aus einer Textbeschreibung und Umwandlung gesprochener oder gesungener Sprache in Text. Letzteres nutzt Whisper.cpp (https://github.com/ggerganov/whisper.cpp) für die Spracherkennung, auf die wir in diesem Artikel ausführlich eingehen. Die KI-Modelle stammen von Open AI, Download und Nutzung sind kostenlos. Whisper erkennt die Ausgangssprache automatisch und erzeugt Text in der gleichen Sprache. Eine Übersetzung ist ebenfalls möglich, allerdings nur in Englisch. Für andere Sprachen benötigt man zusätzliche Tools für die Übersetzung.
Openvino ist eine Intel-Entwicklung und läuft daher optimal auf PCs mit Intel-CPU. AMD-CPUs werden aber ebenfalls unterstützt. Die Grafikeinheit kann zur Beschleunigung eingesetzt werden, was aber nur mit Intel-Hardware funktioniert. Eine NPU (Neural Processing Unit) kann dem gleichen Zweck dienen. Details zu den Hardwarevoraussetzungen finden Sie über https://m6u.de/OPVIN.

Aktuelle Audacity-Versionen für Linux gibt es nur als Appimage-Container, der keine Integration des Openvino-Plug-ins ermöglicht. Deshalb müssen Linux-Nutzer das Programm inklusive Plug-in selbst kompilieren, eine Anleitung dafür finden Sie über https://m6u.de/AUDVIN. Unterstützt werden zur Zeit Ubuntu 22.04/24.04 und darauf basierende Systeme.
Für die einfache Nutzung haben wir die Anleitung in einem Script zusammengefasst. Laden Sie über https://m6u.de/VTTT das Komplettpaket herunter, indem Sie auf „Code“ gehen und dann auf „Download ZIP“ klicken. Entpacken Sie das Archiv im Downloadverzeichnis.
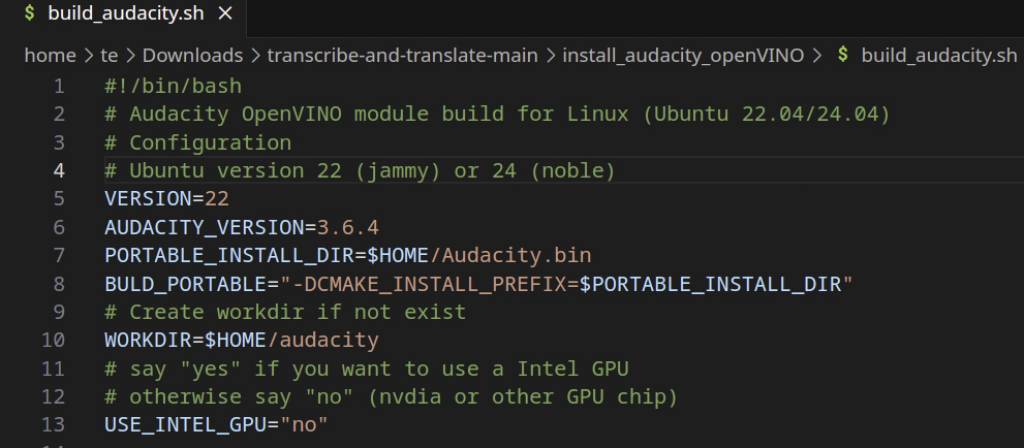
Schritt 1: Öffnen Sie die Datei „build_audacity.sh“ aus dem Ordner „install_audacity_openVINO“ in einem Texteditor. Hinter „Version =“ tragen Sie Ihre Ubuntu-Version ein. Verwenden Sie „22“ für Ubuntu 22.04 (Jammy) oder „24“ für Ubuntu 24.04 (Noble). Falls Sie sich nicht sicher sind, gibt das Terminal mit
cat /etc/os-releaseAuskunft. Hinter „USE_INTEL_GPU=“ andern Sie „no“ auf „yes“, wenn Sie eine Intel-Grafikeinheit verwenden. Die Wahl zwischen „cpu“ und „gpu“ steht in Audacity nur zur Verfügung, wenn die Intel-Grafikeinheit aktiv genutzt wird.
Schritt 2: Wechseln Sie im Terminal in den Script-Ordner und starten Sie mit
bash ./build_audacity.shdas Build-Script. Es installiert zuerst die nötigen Entwicklerpakete aus den Linux-Repositorien, was Sie mit dem Sudo-Passwort erlauben müssen. Danach lädt es weitere Pakete, die für Audacity und Openvino erforderlich sind. Die Operationen finden im Arbeitsverzeichnis „~/audacity“ statt. Es werden außerdem KI-Modelle im Umfang von bis zu 8 GB von https://huggingface.co/Intel/whisper.cpp-openvino-models geladen, was einige Zeit dauern kann.
Schritt 3: Die Installation der Dateien erfolgt im Home-Verzeichnis im Ordner „Audacity.bin“. Damit das Programm alle Bibliotheken findet, muss der Start über
~/Audacity.bin/bin/start_audacity.sherfolgen. Das Installations-Script erstellt auch einen Programmstarter, mit dem sich Audacity später in den „Aktivitäten“ von Gnome oder im Startmenü von Linux Mint und anderen Ubuntus aufrufen lässt.
Audacity konfigurieren und nutzen
Nach dem ersten Start von Audacity gehen Sie auf „Bearbeiten –› Einstellungen“ und dann auf „Module“. Hinter „mod-openvino“ stellen Sie „Aktiviert“ ein und starten Audacity neu. Über „Datei –› Öffnen“ wählen Sie die Datei, die Sie verarbeiten wollen. Audacity kann alle üblichen Mediendateien öffnen, aus Videodateien werden die Tonspuren extrahiert. Markieren Sie die ganze Tonspur per Doppelklick oder markieren Sie mit der Maus einen Bereich. Danach gehen Sie auf „Analyse –› OpenVINO Whisper Transcription“.
Whisper-Konfiguration: Hinter „OpenVINO Inference Device:“ ist „CPU“ voreingestellt, die schnelleren Modi „GPU“ oder „NPU“ stehen zur Verfügung, wenn im PC unterstützte Intel-Hardware steckt. Hinter „Whisper Model:“ geben Sie das gewünschte KI-Modell an. Die Modelle unterscheiden sich in Größe, Geschwindigkeit und RAM-Bedarf, aber auch in der Exaktheit der Spracherkennung. In der Regel empfiehlt sich das etwa größere Modell „medium“.
Hinter „Modus:“ ist „transcribe“ für die Texterkennung eingestellt, hinter „Source Language:“ kann man „auto“ belassen, womit bei unseren Tests Whisper die Sprache zuverlässig erkannt hat. Wenn nicht, stellt man die gewünschte Sprache ein. Der Modus „translate“ übersetzt den erkannten Text in die englische Sprache. Weitere Zielsprachen unterstützt Whisper nicht.
Wenn Sie ein Häkchen vor „Advanced Options“ setzen, können Sie die Arbeitsweise von Whisper ändern. Eine Anweisung hinter „Initial Prompt:“ lädt zu Experimenten ein. Man kann beispielsweise die gewünschte Schreibweise von Produktbezeichnungen oder Personennamen vorgeben, wenn Whisper sie nicht korrekt erkennt. Beispiele dafür sind unter https://cookbook.openai.com/examples/whisper_prompting_guide zu finden. Es genügt „QuirkQuid Quill Inc“ einzutragen, damit Whisper statt „Quirk, Quid, Quill, Inc.“ die Wörter „QuirkQuid Quill Inc“ verwendet. Mit dem Prompt „Remove any of the following german filler words from transcribed text: äh, ähm, eh“ lassen sich unnötige Wörter aus dem Transkript entfernen. Bei unseren Tests hat das allerdings oft nicht zuverlässig funktioniert.
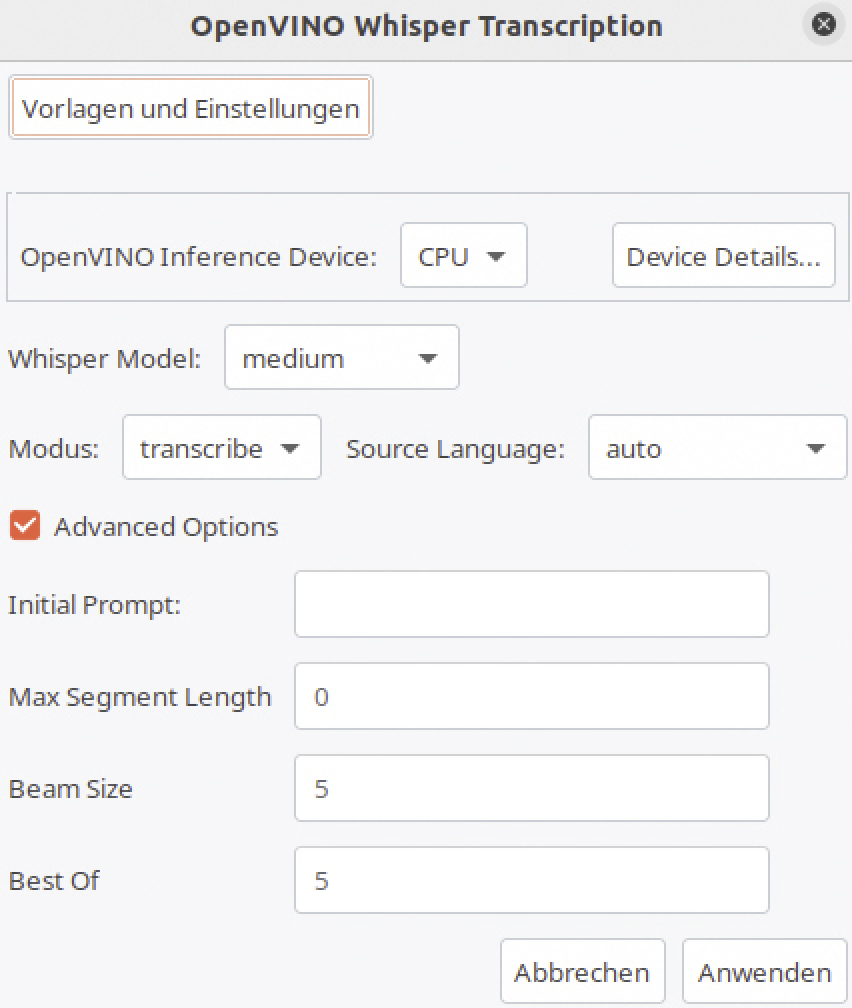
Die Angabe hinter „Max Segment Length“ begrenzt die Länge der Textpassagen in einem Zeitabschnitt. „Beam Size“ und „Best Of“ steuern die Anzahl der Sequenzen, die Whisper bei der Erzeugung von Text verwendet. Höhere Werte können die Spracherkennung verbessern, benötigen aber mehr RAM und Rechenzeit.
Transkript exportieren: Audacity zeigt den Text in einer eigenen Spur an, die Sie anklicken und dann auf „Datei –› Andere exportieren –› Textmarken exportieren“ gehen. Rechts unten wählen Sie das gewünschte Format. „Textdateien“ enthält zwei Spalten mit Zeitstempeln und daneben jeweils eine Zeile mit dem transkribierten Text. „SubRip-Textdatei“ ist das verbreitete Format für Mediaplayer und „WebVTT-Datei“ eignet sich für in Webseiten eingebettete Player.
Automatisch transkribieren und übersetzen
Audacity lässt sich über die Oberfläche bequem nutzen. Wer jedoch regelmäßig mehrere Dateien transkribieren und den Text auch in andere Sprachen übersetzen will, kann das mit einem Script erledigen. Zum Einsatz kommt Whisper wie bei Audacity, Übersetzungen erledigen ein Onlineübersetzer oder ein lokal installiertes KI-Modell. Eine eigene Installation von Whisper kann außerdem zusätzlich eine Nvidia-GPU für die Hardwarebeschleunigung verwenden.
Scripts installieren: Aus dem Download von https://m6u.de/VTTT starten Sie „install-python-scripts.sh“ aus dem Ordner „install_python_trans“. Es installiert alle nötigen Systempakete und die Python-Module im Ordner „python-trans“ im Home-Verzeichnis (siehe Kasten „Virtuelle Python-Umgebungen“). Die Installation ist mit ungefähr 6 GB umfangreich, hinzu kommt noch der Platz, den der Cache und die KI-Modelle belegen.
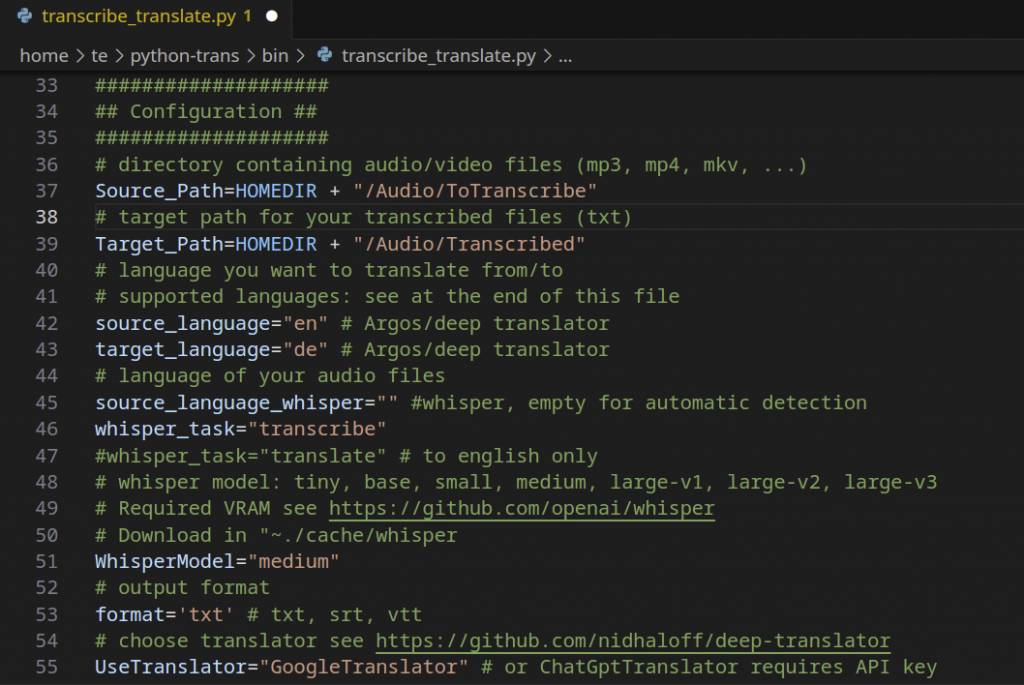
Scripts konfigurieren: Öffnen Sie das Script „python-trans/bin/transcribe_translate.py“ in einem Texteditor. Im oberen Bereich sehen Sie einen Abschnitt mit Variablen für die Konfiguration. Die Zeile
Source_Path=HOMEDIR + "/Audio/ToTranscribe"gibt an, in welchem Ordner sich die Dateien befinden, die das Script verarbeiten soll. Erstellen Sie den Ordner „~/Audio/ToTranscribe“ oder tragen Sie einen anderen Pfad ein, den Sie verwenden wollen. Entsprechend legt
Target_Path=HOMEDIR + "/Audio/Transcribed"den Zielordner fest, der ebenfalls vorhanden sein muss.
Hinter „source_language=“ und „target_language=“ steht jeweils der Ländercode für die Übersetzung von der Sprache des Ausgangsmaterials in die Zielsprache. Eine Liste mit Codes finden Sie am Ende der Datei.„format=“ legt das Format der Ausgabedateien fest. „txt“ steht für eine einfache Textdatei und „srt“ oder „vtt“ für Untertiteldateien.
Das Script kann mehrere Übersetzungsdienste verwenden. Bei
UseTranslator="Argos"kommt der Argos-Übersetzer (https://github.com/argosopentech/argos-translate) mit einem lokalen Sprachmodell zum Einsatz. Der Google-Übersetzer liefert bessere Ergebnisse, greift aber auf den Onlinedienst zurück. Um ihn zu verwenden, geben Sie
UseTranslator=“GoogleTranslator“
an. Das Python-Modul Deep-Translator kann auch andere Übersetzer verwenden, beispielsweise ChatGPT. Dieser Dienst ist jedoch kostenpflichtig und Sie benötigen dafür einen API-Schlüssel (https://platform.openai.com/account/api-keys), den Sie hinter „api_key=“ eintragen. Weitere Infos zu den verfügbaren Diensten lesen Sie auf der Webseite des Modulentwicklers (https://github.com/nidhaloff/deep-translator).
Tragen Sie hinter „whisper_task=“ den Wert „translate“ ein, wenn Sie nur eine englischsprachige Übersetzung benötigen.
Audacity-Dateien übersetzen: Das Script „~/python-trans/bin/translate_audacity_files.py“ dient zur Verarbeitung von Dateien, die Sie mit Audacity erstellt haben. Aus „.txt“-Dateien entfernt das Script die Zeitstempel in der Übersetzung, Untertiteldateien übersetzt es unter Beibehaltung des Formats. Das Script berücksichtigt alle Dateien, die im hinter „Source_Path=“ angegebenen Ordner liegen und speichert die Übersetzungen im Pfad hinter „Target_Path=“. Die Sprachen von Quell- und Zieldatei legen Sie hinter „source_language=“ und „target_language=“ fest. Die Konfiguration des Übersetzers übernimmt das Script aus der Datei „python-trans/bin/transcribe_translate.py“.
Script starten: Im Terminal starten Sie die Scripts mit
~/python-trans/bin/transcribe_translate.pybeziehungsweise
~/python-trans/bin/ translate_audacity_files.pyFür den vereinfachten Aufruf nehmen Sie das Verzeichnis in den Pfad auf. Dafür tragen Sie die Zeile
PATH="$HOME/python-trans/bin:$PATH"in die Datei „~/.profile“ ein, die Sie mit
source ~/.profileneu einlesen. Die Angabe wird dadurch sofort im aktuellen Terminal wirksam.
Untertitel verwenden oder integrieren
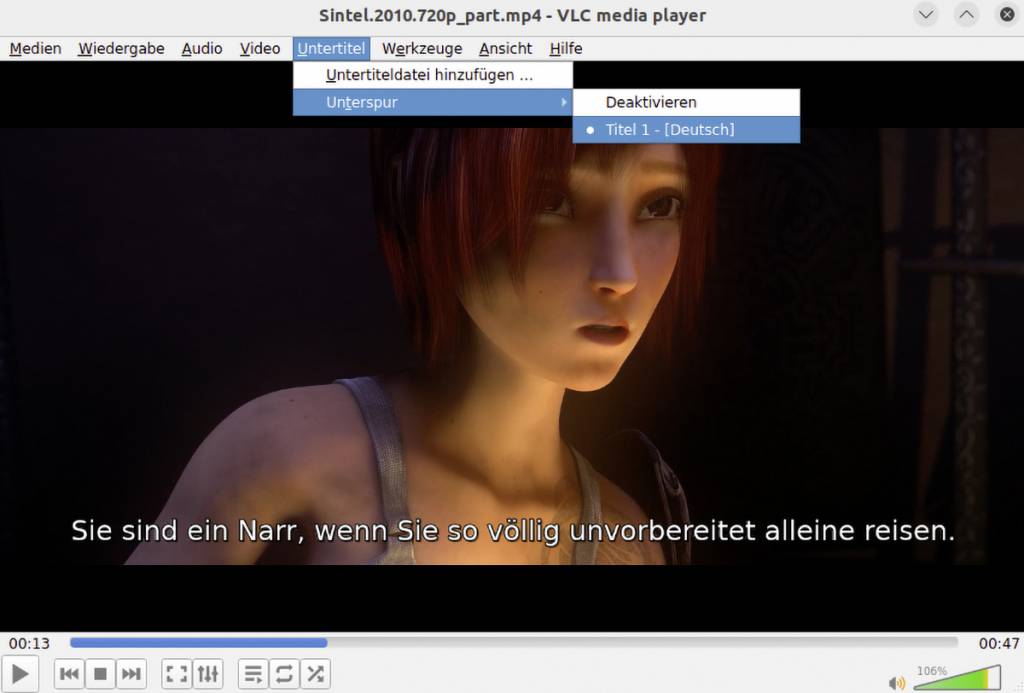
Der VLC-Player zeigt Untertitel auch bei Audiodateien an, wenn Sie unter „Audio –› Visualisierungen“ beispielsweise „Spektrometer“ aktivieren. Untertiteldateien erkennt VLC bei Audio- und Videodateien automatisch, sofern deren Name identisch ist mit dem der Mediendatei. Andernfalls gehen Sie auf „Untertitel –› Untertiteldatei hinzufügen“. VLC unterstützt Dateien um Subrip- und Webvtt-Format.
In Videos baut man Untertitel am einfachsten mit Handbrake ein (https://handbrake.fr). Für Linux gibt es diesen Videokonverter im Flatpak-Container. Linux Mint unterstützt Flatpak standardmäßig, Nutzer von Ubuntu finden eine Anleitung unter https://www.pcwelt.de/1182357.
Öffnen Sie in Handbrake die Videodatei, wählen dort das gewünschte Ausgabeformat und passen bei Bedarf den Videoencoder auf der Registerkarte „Video“ an. Auf der Registerkarte „Untertitel“ klicken Sie auf „Spuren –› Neue Spur hinzufügen“. Unter „Track name“ tragen Sie einen Ländercode ein, also beispielsweise „ger“ für Deutsch. Unter „Language“ stellen Sie die Sprache der Untertiteldatei ein und hinter „File:“ wählen Sie die gewünschte Untertiteldatei. Klicken Sie auf „Speichern“. Wiederholen Sie diese Schritte für alle Untertitelspuren, die Sie in das Video einfügen wollen.
Ein Beispiel für Videos mit Untertitelauswahl in Webseiten zeigt der Ordner
„HTML-Demo“ aus dem Download von https://m6u.de/VTTT. Das HTML aus der Datei „index.html“ funktioniert nur beim Abruf vom Webserver, nicht aber beim Öffnen vom lokalen Laufwerk. Wie das Ergebnis aussieht, können Sie auf https://m6u.de/VTTDEM sehen.
Zusätzliche Info: Virtuelle Python-Umgebungen
Python-Module installiert man aus Stabilitätsgründen bevorzugt aus den Paketquellen der Linux-Distribution.
Ist das Gesuchte dort nicht vorhanden, lassen sich weitere Module über das Tool pip aus einer Fremdquelle installieren. Damit keine Systempakete beeinträchtigt werden, sollte man dabei immer in einer virtuellen Python-Umgebung arbeiten, die sich mit python -m venv [Ordner] erstellen lässt. Mit
source ~/[Ordner]/bin/activateaktiviert man die Umgebung im Terminal und arbeitet wie gewohnt mit Python. Alle Befehle darin wirken sich nur auf den Ordner der virtuellen Umgebung aus, auch bei „pip install [Paketname]“.
Ein Python-Script kann man mit
~/[Ordner]/bin/python3 [script.py]starten, wodurch es nur in der virtuellen Umgebung arbeitet. Zur Sicherheit sollte in eigenen Scripts in der ersten Zeile immer
#!/home/[User/Ordner]/bin/python3stehen, damit es garantiert in der virtuellen Umgebung gestartet wird.